Model Context Protocol(MCP)简单上手
MCP(Model Context Protocol)说白了就是一种接口协议,可以让各种外部应用以工具的方式被大模型调用。工具调用不算很新的概念,现在的各种联网、画图功能就是属于这种。cline前段时间更新MCP市场的时候我就关注到了MCP,不过没有太多重视,当时只觉得多了一些好用的工具。直到后来我看到了基于claude-3.7+搜索插件的简单agent,不需要复杂工作流,就可以实现搜索-反思-再搜索-总结这样的复杂功能。可以说现在的大模型加上各种工具所拥有的能力和自主性已经远远超出了我的预期。而作为Anthropic主推的接口协议,MCP凭借其开放性和灵活性自然获得了极大的关注。
一、MCP配置和使用
MCP的使用说起来并不复杂,需要完成三个步骤:
1. 选择一个支持MCP的客户端
2. 安装MCP服务,完成必需的配置
3. 在支持function call的大模型里调用
作为 cherry studio 的忠实用户,我当然是选择 cherry studio 作为我的第一个MCP客户端啦。cherry studio 的MCP功能是最近更新的,目前bug很多,功能时好时坏,而且经常连报错信息都没有,实在说不上好用,不过用来体验一下还是可以的。
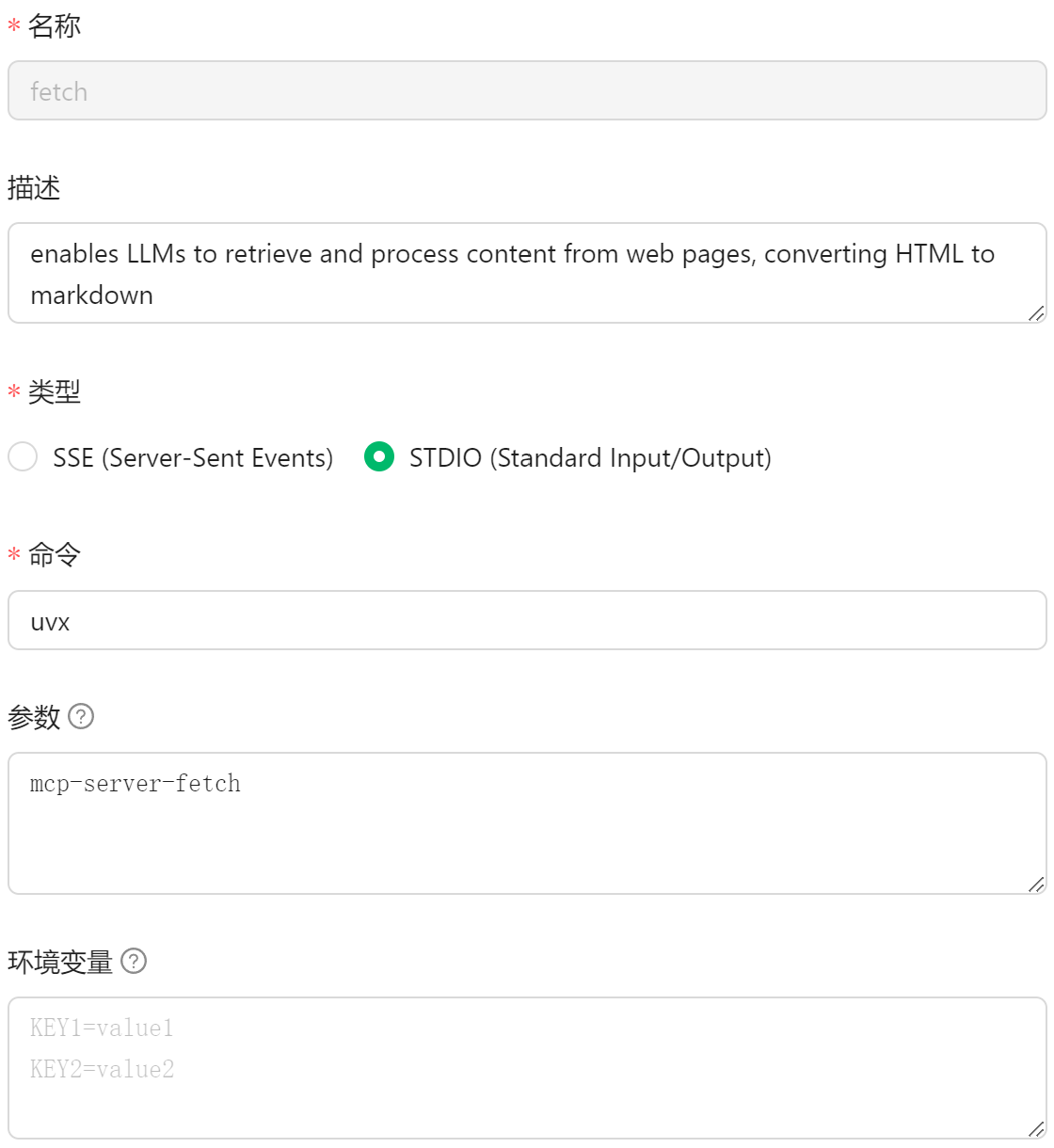
然后是MCP服务的选择,刚上手的话肯定是要挑一个简单的。这里选择cherry studio官方教程里面推荐的mcp-server-fetch 服务。这是一个本地部署的网页抓取服务,配置较为简单。
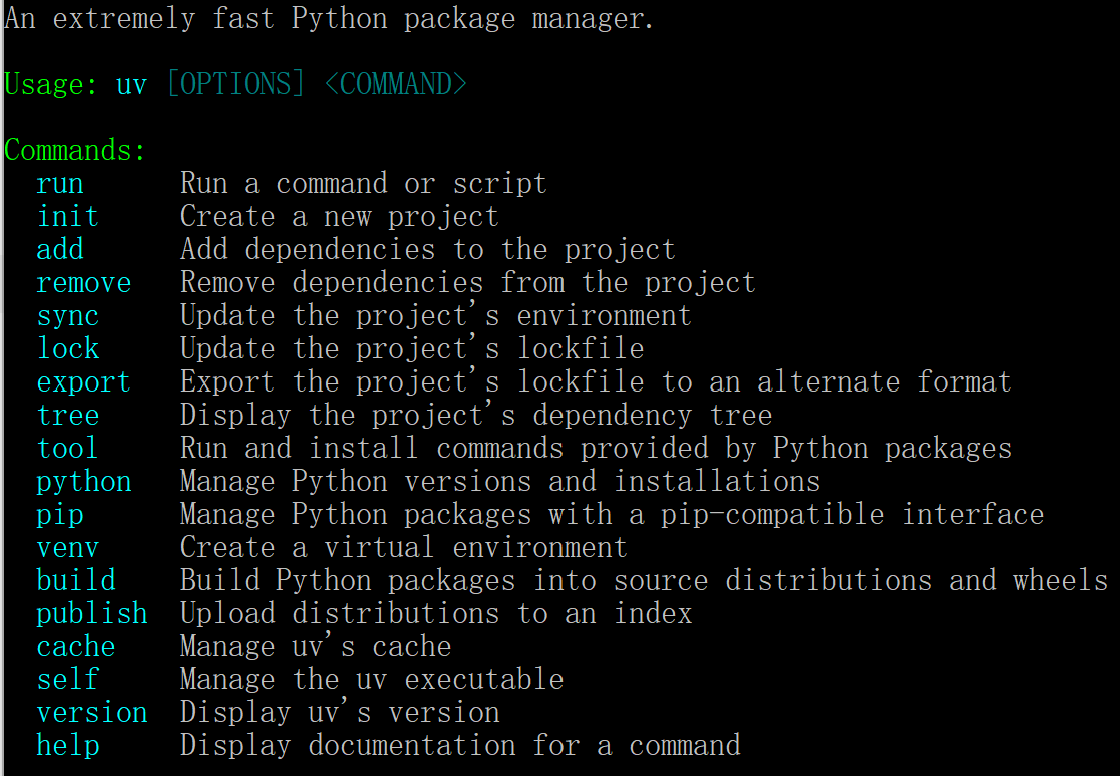
安装之前需要确保本地安装有uv,如果没有就 pip install uv 安装一下。最好是安装在系统环境的python下,不然调用的话就需要用绝对路径来调用。安装完成后在cmd中输入uv,出现如下页面说明环境没有问题:
mcp服务最关键的就是其配置文件,例如mcp-server-fetch给的配置文件是这样的
1 | |
这个配置很容易理解,主要包括command和args两部分。就是使用uvx(uv自带的)来启动mcp-server-fetch。cherry studio的MCP配置界面是如下所示,和上面的配置文件是对应的。把命令和参数填到对应方框中就好了。有些复杂的MCP可能还需要设置env环境变量,也一一对照填进去就可以了。当然,现在的版本bug很多,配置好了也不保证能启动起来。
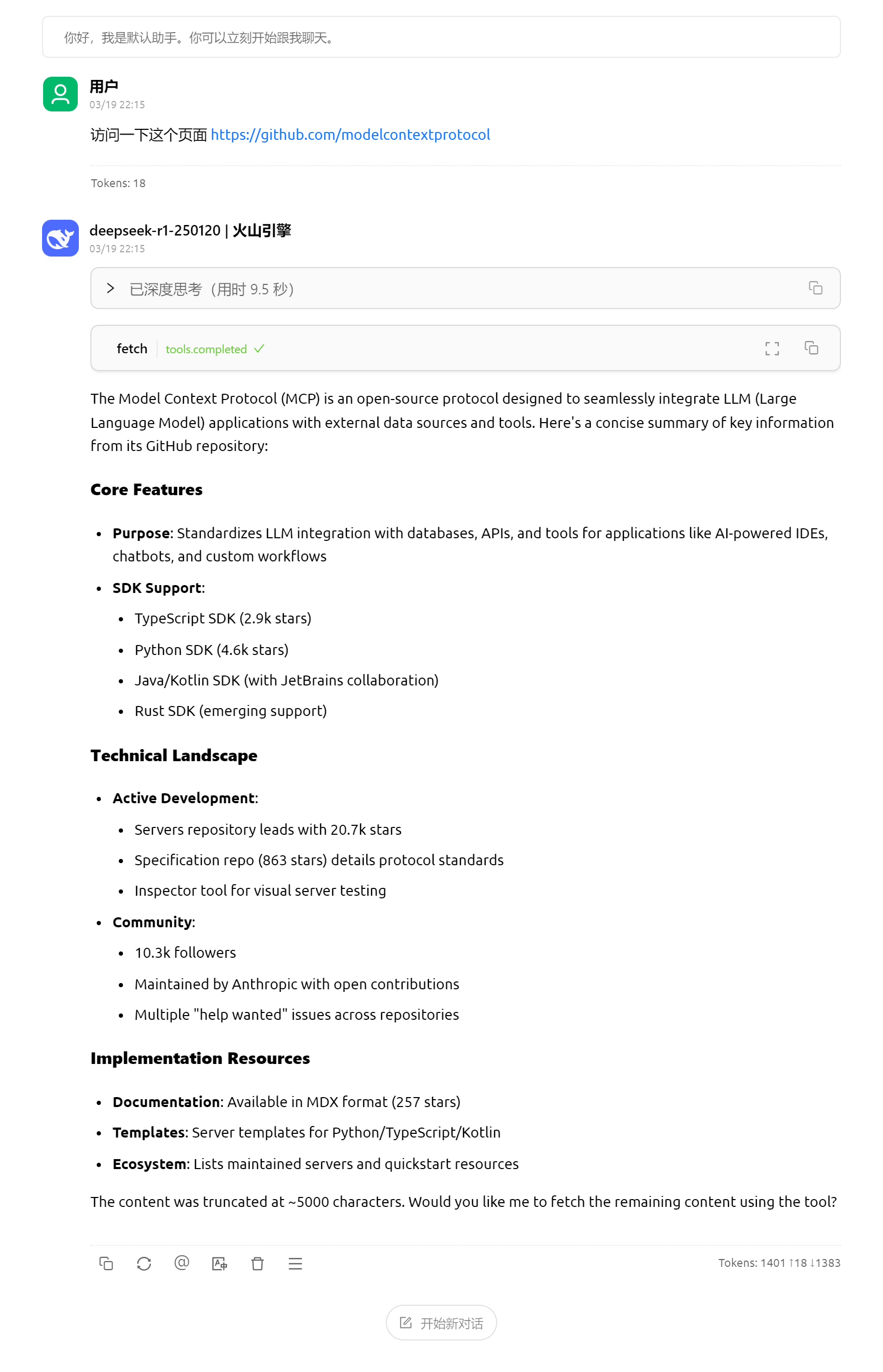
目前deepseek工具调用的其实不是很完善,尤其是使用搜索和网页爬取工具的时候,经常会获取一大堆内容,然后撑爆上下文导致报错。而且deepseek的多轮调用积极性并不高,一般调用几下就马上给出结果了。如果要多轮调用的话最好使用Claude-3.7,而要确保调用功能流畅性的话gpt效果也很好。另外这里还发现一件有意思的事情,deepseek-r1的工具调用是在思考的时候进行的。思考到一半然后去调工具,调完回来接着思考,其他模型都是在正文里面去调用的。不知道是不是因为这个导致调用效果较差。
二、基于MCP功能实现简单应用
我一直想做一个根据知识库里面的内容做文献综述、深度研究的应用。之前研究了很久的知识库和工作流,最后实现的效果实在是一般。现在刚好可以试试MCP在这种复杂应用中的能力。
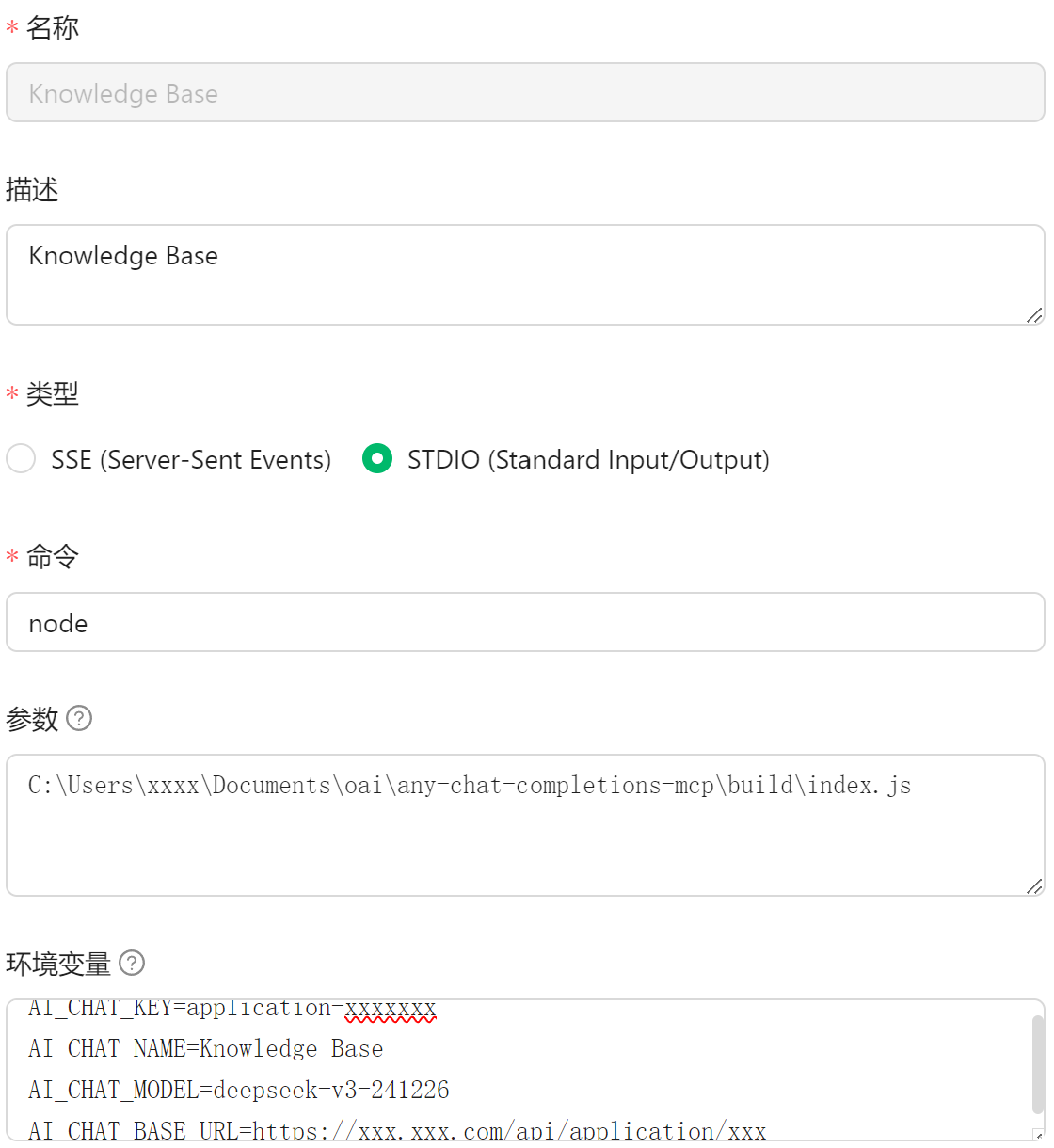
那么问题来了,怎么把知识库集成到MCP中呢。我这里用了一种取巧的方法,就是利用这个MCP服务:any-chat-completions-mcp 。这个服务可以把支持openai接口的对话模型转化为MCP,一些常用的知识库例如fastgpt、maxkb等都是支持openai接口的,这样大语言模型就可以通过对话获取知识库信息了。cherry studio的配置界面如下,需要注意的是AI_CHAT_NAME这个环境变量既是工具名称,也是工具描述,所以需要体现知识库的功能,这样模型才好去调用。
对于这种长文归纳、总结的应用,目前Claude-3.7的效果是最好的,不过即使是Claude-3.7在调用工具的时候也有偷懒的表现。这里我用提示词进一步提升了Claude的调用积极性:
1 | |
这里我用maxkb搭了一个简单的知识库,里面放了deepseek在arxiv上面的七八篇文章。用豆包的嵌入模型来矢量化,用deepseek-v3来总结知识库内容,最后使用MCP接入到Claude-3.7中。效果可以参考下面的图片,我让Claude研究了一下deepseek的技术路线。因为用提示词进行了增强,claude进行了8轮的知识库搜索,给出了一篇还算不错的报告。我知识库搭的确实有点随意,这么多轮搜索都没有出现deepseek-r1的内容,不过MCP整体的运作流程还是比较让人满意的。
知识库深度研究

总的来说MCP确实让大模型的能力得到了飞跃式的提升。而且这种大模型自主决定用什么工具、怎么用工具的调用方式,确实比死板的工作流用起来舒服。技术进步的本质其实就是偷懒,既然大模型自己就能完成复杂流程,大家为什么要苦哈哈地手动去搭建工作流呢。可想而知,以后这种自主工作的agent会越来越多,大家主要负责监工就好了。
最后,推荐一些比较好用的mcp server网站:
1. PulseMCP | Keep up-to-date with MCP
2. Smithery - Model Context Protocol Registry
4. MCP Servers